Kafka: Suksess i en Sanntidverden
De siste årene har vært preget av betydelige skifter innen både forretnings- og teknologitrender. I respons til disse endringene har mange organisasjoner valgt å implementere Apache Kafka som en løsning for å håndtere de utfordringene som disse trendene presenterer. Før vi dykker inn i essensen av Apache Kafka, er det hensiktsmessig å få innsikt i de spesifikke typer utfordringer og problemer som Kafka effektivt kan løse.
Trender
På forretningsfronten har det skjedd betydelige endringer i måten applikasjoner samhandler med brukere på. Bare for noen få år siden var applikasjonene hovedsakelig statiske og "dumme," der data fra forrige uke var tilstrekkelig. Nå forventes applikasjoner i økende grad å reagere i sanntid med "sanntidsintelligens," og gi umiddelbare varsler til brukeren ved relevante hendelser. Denne forventningen skaper ekstra kompleksitet, spesielt siden hendelsene ofte stammer fra ulike systemer i forskjellig infrastruktur, inkludert fysiske maskiner og skytjenester.
En annen dominerende trend er håndteringen av store mengder data gjennom prosessering og analyse. Dette gjelder spesielt for data fra sensorer, overvåking av kontobevegelser i banker, eller analyse av medisinske data for å forutsi sykdommer, epidemier og lignende.
Teknologitrender som mikrotjenester og cloud native-konsepter har også blitt betydningsfulle. Disse trendene, inkludert respons på hendelser fra ulike kilder, analyse og prosessering av store datamengder, samt bruk av mikrotjenester og cloud native-arkitekturer, harmoniserer særlig godt med Apache Kafka.
Eksempler på use cases for Kafka:
-
Tracking av aktivitet på websider
-
Monitorering av nettverk
-
Internet of Things
-
Innsamling og monitorering av statistikk
-
Aggregering av logger
Men hva er Kafka?
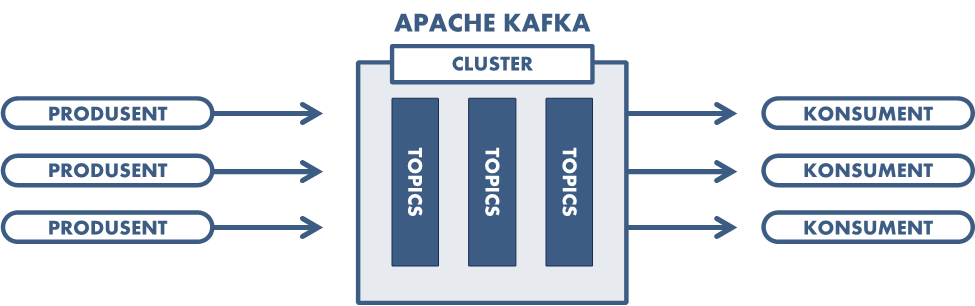
Apache Kafka er en såkalt streamingplattform. I denne sammenhengen kan begrepet streaming forstås som en kontinuerlig strøm av hendelser (events). Hendelsene kommer typisk fra flere forskjellige kilder (produsenter) i en distribuert arkitektur. Hendelsene puttes deretter på en topic. På den andre siden av Kafka-clusteret har man konsumenter, og konsumentene abonnerer på topics som de har interesse av. Man kan sammenligne dette med en avis, vi har produsenter som «publiserer» aviser, og konsumenter som kjøper aviser de er interessert i. Apache Kafka er altså en hendelsesdrevet (event driven) plattform, og fungerer på mange måter som en typisk publisher/subscriber-plattform, ikke helt ulikt et meldingssystem (message broker).
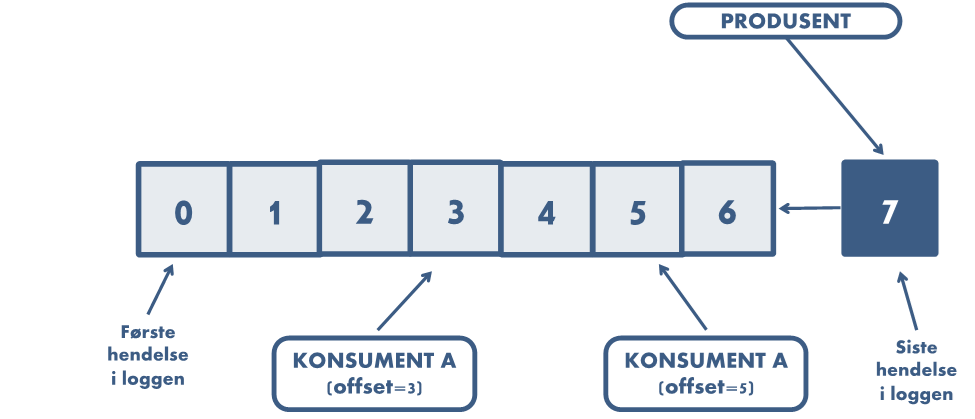
Et vesentlig poeng med Kafka er den permanente lagringen av hendelser i offset logs. Dette gir en vedvarende historikk av hendelser, og mye av Kafka's funksjonalitet dreier seg om håndtering og prosessering av disse loggene. Dette muliggjør ikke bare sanntidsbehandling av hendelsesstrømmen, men gir også pålitelig og sporbar historikk for analyse og gjenoppretting.
Mens Kafka fungerer som en database ved å lagre data permanent, skiller det seg fra tradisjonelle relasjonelle databaser. Sistnevnte er effektive for strukturerte data, men har begrensninger som hindrer tilpasning til moderne trender. For eksempel mangler de optimalisering for kontinuerlig prosessering med lav latenstid, som er en styrke hos Kafka. Videre er skalering av tradisjonelle databaser utfordrende, mens Kafka, spesielt i skybaserte miljøer, enkelt muliggjør skalering. Dette gjør Kafka attraktivt i mikrotjeneste- og cloud native-arkitekturer, der enkel skalering er en av de betydelige fordelene.
Managed Kafka (Kafka as a Service)
Kafka kan være utfordrende å administrere, spesielt når det gjelder drift (Ops). Skalerbarhet, feilhåndtering, elastisitet og sikkerhet krever manuell håndtering og da gjerne gjennom kode, «properties», Admin API’er eller lignende. For å takle denne kompleksiteten, tilbys flere alternativer for å kjøre Kafka som en «Managed Service». Da vil man vanligvis få Kafka pakket sammen med hjelpetjenester for å håndtere infrastruktur, prosessere data, sikkerhet og for å holde oversikt over Kafka clusteret.
Å oppnå skalerbarhet er en av de mest utfordrende aspektene ved å etablere et Kafka-miljø. Man må ha et system som kan håndtere plutselige trafikktopper i nåtiden og samtidig være bygget for å takle fremtidig trafikk, som ofte er vanskelig å forutsi. Med Kafka i skyen tilbyr de fleste tjenester elastisk skalering uten behov for endringer. Dette ikke bare minimerer risikoen for nedetid og feil i applikasjonene, men sikrer også kostnadseffektivitet ved kun å betale for faktisk bruk. I motsetning, on-premise Kafka-konfigurasjoner kan føre til overdimensjonering for å unngå nevnte problemer, resulterende i unødvendige kostnader. Det er verdt å merke seg at en solid Kafka-arkitektur er avgjørende for vellykket skalerbarhet, både i skyen og on-premise.
Med managed Kafka har man også fordelen av SLAs og utvidede supportløsninger, og bedriften kan derfor fokusere på det som er viktig, nemlig å løse problemer.
Apache Kafka er en streamingplattform som brukes til å håndtere utfordringene med sanntidsinteraksjon og stor datamengde. Den støtter implementering av mikrotjenester og cloud native-arkitekturer, og gir pålitelig lagring av hendelser for analyse og gjenoppretting. Administrasjonen av Kafka kan være kompleks, derfor tilbys det også "Managed Kafka" tjenester som tar seg av infrastruktur, sikkerhet og skalerbarhet. Dette gjør det lettere for organisasjoner å fokusere på problemløsning istedenfor administrasjon.
Vil du lese mer:
