Monitorering av integrasjoner
Skrevet av: Tom Sverkmo og Anders Edh
Mange har opplevd et produksjonsproblem der man febrilsk søker gjennom lange og uoversiktlige systemlogger etter årsaken til feilen. Bare å finne riktig logg å lete i kan være utfordrende. Presset blir heller ikke mindre når du har et par ledere som puster deg i nakken, eposter som plinger og chattekanaler som går varmt, alle med samme beskjed: "Løs problemet NÅ!!"
I et komplekst integrasjonslandskap, hvor integrasjonene inneholder mye funksjonalitet og logikk og mange ulike systemer og løsninger er koblet sammen, kan feilsøking være utfordrende. Da er man avhengig av en løsning som øyeblikkelig informerer at en feil har oppstått, hvor feilen oppstod og hva som var årsaken - med dagens teknologi kan det til og med være mulig å forutsi at feil kommer til å skje.
Da har men behov for en god løsning som overvåker og monitorerer integrasjonene
Fokuser på kommunikasjon mellom systemene
Det finnes flere ulike løsninger for å monitorere integrasjoner. Alt fra leverandørbaserte løsninger, tilpasset den integrasjonsplattformen man benytter, til uavhengige løsninger som fungerer på tvers av de ulike plattformene. Noen henter informasjon fra loggefiler, da er forutsetningen at det logges i et format med innhold som monitoreringsløsningen kan tolke og forstå. Andre lytter til meldinger som går på tvers av systemer, da må det være såkalte agenter som fanger opp meldinger.
God monitorering bør oppfylle 5 kriterier:

1. Varsling
Først og fremst er det viktig å bli varslet dersom noe ikke er som det skal. De ulike løsningene har ofte flere måter å varsle på, mest vanlig er "alarm" og "advarsel". For å få et system til å sende ut et varsel må det settes noen regler;
- Hva skal utløse alarm eller advarsel?
- Er det ved tjenestefeil en gang? Ved 20% av tiden?
- Er det ved rare eller uvanlige svar?
En viktig del av en slik løsning er å kunne lage fleksible regler basert på ulike behov, samt lett å endre ved endring i behov. Varsling til riktig ressurs til rett tid er også kritisk ift å raskt kunne løse problemet, enten det er mail til en teknikker eller en overvåkningsløsning.
2. Proaktivitet
Det er en ting å reagere på at en bruker sender mail og sier noe ikke virker, men hva om man kunne fange opp denne feilen før noen legger merke til det? Eller før det feiler i det hele tatt? Med et proaktivt monitoreringsverktøy kan man for eksempel se etter trender i svartid på tjenester eller antall feil som dukker opp. Med mulighet for å sette regler kan man få et varsel om at tjenesten fusker før det oppdages, og påvirker, brukere og omkringliggende systemer
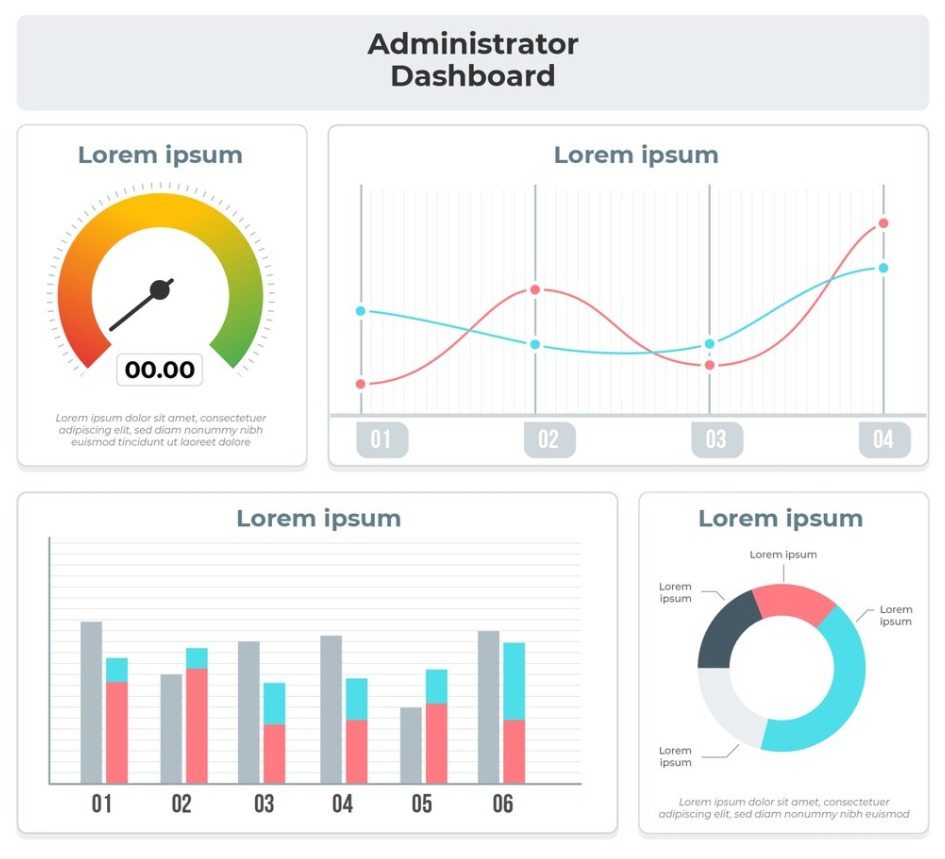
3. Dashboard
Til tross for at monitoreringsverktøy bare kjører og er usynlig for de fleste, må det være synlig for noen. Det blir kanskje sendt en mail eller opprettet en sak ved feil, men en god måte å få oversikt er å benytte grafiske dashboards som viser status for de kritiske systemene som overvåkes. I integrasjoner for eksempel, ønsker man gjerne å se forholdet mellom de forskjellige nodene. Det bør være mulig å tilpasse dashboardet til akkurat det du har behov for å følge med på, om det er antall tjenestekall på en dag eller antall feil.
4. Sporbarhet
I flere monitoreringsløsninger får man, out of the box, mulighet til å se hvor mange feil som skjer. Det betyr ikke nødvendigvis at informasjonen er tilstrekkelig, da den kanskje kun sier noe om at en tjeneste har feilet, men ikke hvor. Hvis man ser for seg en integrasjonsflyt med mange steg, kan det ta lang tid å finne ut hvor feilen oppsto. I gode løsninger vil verktøyet kunne fortelle deg hva som skjedde, hvor det skjedde og hvorfor det skjedde.
I mange tilfeller er det endringer av kode eller konfigurasjon som forårsaker at integrasjoner feiler. For å fange opp slike hendelser raskt bør man ha løsninger som fanger opp dette. Med en god monitoreringsløsning vil det være mulig å knytte feil som oppstår til endringer som er produksjonssatt. I noen løsninger finnes det også muligheter for å automatisk rulle tilbake endringer som forårsaker brudd.
5. Synlighet
Det kan være nyttig å se sammenhenger i systemene som snakker sammen. Med god visibility eller synlighet kan man enklere se hvor trafikk går, med hvilken hastighet, datamengde og lignende. Dette er god måte å bruke overvåkningsdata til noe mer enn bare å finne feil, men også til å se trender og momenter i dataen.
De 5 kriteriene ovenfor er med på å redusere avbrudd, og forbedre ytelsen på integrasjonene i en organisasjon. Problemer og flaskehalser kan avdekkes slik at man heller kan fokusere på forbedring på disse områdene. Man er mer forberedt på situasjoner som oppstår, og i mange tilfeller kan de oppdages før det påvirker forretningsdriften.
Hvorfor monitorering?
Det finnes flere ulike verktøy i markedet som er i stand til å ivareta monitorering av integrasjoner. Det viktigste er at organisasjonen tar et standpunkt til om man skal monitorere integrasjonene for så at det settes av tid og ressurser til å implementere en slik løsning.
Vi i Avella har i mange år drevet med utvikling og drift av integrasjoner ved bruk av forskjellige mellomvareløsninger. Kompleksiteten på løsningene vi har utviklet har variert fra enkle integrasjoner mellom få systemer, til store og komplekse integrasjoner mellom mange systemer. Hos flere av våre kunder har vi vært med på å implementere monitorering av integrasjoner, både uavhengige- og skreddersydde løsninger. Erfaringene vi har gjort oss er at en god monitoreringsløsning er avgjørende for å sikre drift og stabilitet, og at en slik løsning blir mer uvurderlig for forretningen dess større og mer komplekse integrasjoner bedriften har.

Har du spørsmål eller vil vite mer om hvordan vi jobber med integrasjon og monitorering av integrasjoner?
Ta kontakt med vår salgssjef Ole Morten Boldevin på boldevin@avella.no eller på telefon 928 38 279.