Hvorfor Kafka?
Før man begir seg inn på hva Apache Kafka faktisk er, kan det være nyttig å vite noe om hva slags type utfordringer og problemer Kafka løser og hvorfor så mange aktører i dag velger å bruke Kafka.
De siste årene har man sett forandringer i både forretningstrender og teknologitrender. På forretningssiden har man kunnet se en endring i måten applikasjoner samhandler med brukere på. Frem til bare for noen få år siden var applikasjonene typisk statiske og "dumme", og gårsdagens eller forrige ukes batch med data var gjerne mer enn godt nok. Nå forventes det i større grad at applikasjoner responderer på hendelser med "sanntidsintelligens", og umiddelbart gir brukeren beskjed dersom relevante hendelser oppstår. For å gjøre det ennå mer utfordrende, så kommer gjerne hendelsene fra flere systemer i forskjellig infrastruktur. Noe fra fysiske maskiner, noe annet fra skytjenester osv. En annen fremtredende trend er prosessering og analyse av store mengder data, for eksempel fra sensorer som måler luftkvalitet, kontobevegelser hos en bank eller analysering av medisinske data for å kunne forutse sykdom, epidemier eller lignende. Når det gjelder teknologitrender, så er både mikrotjenester og cloud native-begreper som har stor relevans i dag. Alle disse trendene, respons på hendelser fra ulike kilder, analyse og prosessering av big data, mikrotjenester og cloud native, spiller svært godt på lag med Apache Kafka.
Eksempler på use cases for Kafka:
- - Tracking av aktivitet på websider
- - Monitorering av nettverk
- - Internet of Things
- - Innsamling og monitorering av statistikk
- - Aggregering av logger
Så hva er Kafka?
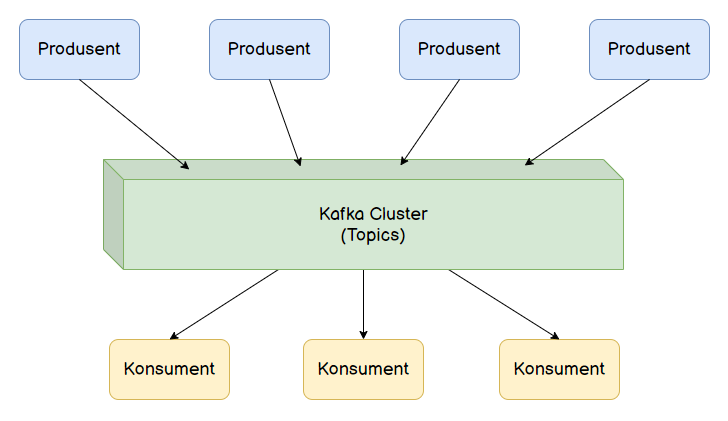
Apache Kafka er en såkalt streamingplattform. I denne sammenhengen kan begrepet streaming forstås som en kontinuerlig strøm av hendelser. Hendelsene kommer typisk fra flere forskjellige kilder (produsenter) i en distribuert arkitektur. Hendelsene puttes deretter på en topic. På den andre siden av Kafka-clusteret har man konsumenter, og konsumentene abonnerer på topics som de har interesse av. Apache Kafka er altså en hendelsesdrevet plattform, og fungerer på mange måter som en typisk publisher/subscriber-plattform, ikke helt ulikt et meldingssystem (message broker).
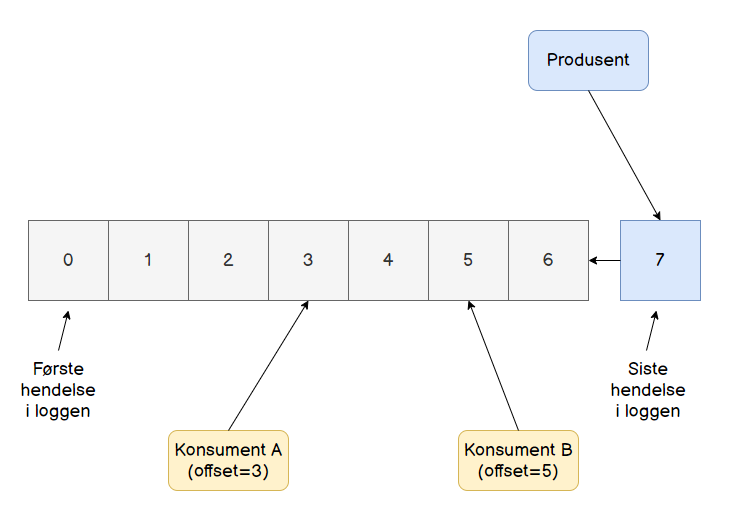
Et vesentlig poeng med Kafka er at hendelsene som ankommer Kafka-clusteret lagres permanent i offset logs, en struktur som man utelukkende tilføyer hendelser til. Svært mye av funksjonaliteten i Kafka dreier seg om å håndtere og prosessere disse loggene på en eller annen måte.
Med data som lagres permanent, så kan man tenke seg at Kafka fungerer som en database, og på mange måter er det riktig. Det er likevel forskjeller på typiske relasjonelle databaser og måten Kafka håndterer data på. De tradisjonelle databasene er svært gode på strukturerte data, og spiller en svært viktig rolle i de aller fleste systemer. De har likevel noen begrensninger som gjør at de er vanskelige å få til å spille på lag med trendene som ble nevnt i første avsnitt. For eksempel er de fleste databaser ikke optimalisert for kontinuerlig prosessering av meldinger med lav latenstid, i motsetning til Kafka. I tillegg er det ikke helt rett frem å skulle skalere en tradisjonell database. Noe av det som gjør mikrotjenester og cloud native attraktivt i dag er at det er vesentlig enklere å skalere applikasjoner og tjenester som er bygget på denne arkitekturen enn store, såkalte monolitt-applikasjoner. Skalering er et av fortrinnene til Kafka, og siden det i tillegg kjører i skyen, så trenger ikke skalering av Kafka å være noen komplisert affære.
Managed Kafka (Kafka as a Service)
Kompleksiteten i Kafka kan være en utfordring, og da spesielt det som har med drift (Ops) å gjøre. Skalerbarhet, feilhåndtering, elastisitet og sikkerhet er bare noe av det som må håndteres manuelt. På grunn av denne kompleksiteten finnes det mange alternativer for å kjøre Kafka som en skytjeneste. Hensikten med Kafka i skyen er at mange av disse potensielle problemområdene minimeres. Fokusområdet skal være på problemet man forsøker å løse og dets utfall, og ikke på infrastruktur.
Skalerbarhet er blant de største utfordringene når det kommer til å bygge et Kafka-miljø. Man trenger et miljø som håndterer plutselige trafikktopper i dag, og det må bygges for å tåle fremtidens trafikk, som er vanskelig å forutse. Med Kafka i skyen får man i de fleste tilfeller elastisk skalering uten å måtte endre noe som helst. Ikke bare reduserer dette sjansen for nedetid og feil i applikasjonene dine, men det sikrer også at man ikke betaler for mer enn hva man faktisk bruker. Alternativet på en on-premise Kafka er at man gjerne over-skalerer for å hindre de nevnte tilfellene, og derfor betaler mer enn man behøver.
Med managed Kafka har man også fordelen av SLAs og utvidede supportløsninger, og bedriften kan derfor fokusere på det som er viktig, nemlig å løse problemer.

